Appendix A — Data Mining
- Data Mining
-
The scientific art of extracting meaning from data using models.
–Scientific: Applied statistics is the core of data mining.
–Art: Informed qualitative decisions guide all data mining.
–Meaning: Stories emerge from data as we apply statistics and make decisions in the data mining process.
–Models: Mathematical representations of relationships in a data set.
Data mining plays a significant role in the data analytics cycle (Figure A.1). There are many approaches to this cycle, including CRISP-DM, SEMMA, KDD, etc. (see Hotz 2023 for comparisons; and Biecek and Burzykowski 2020, sec. 2.2 for a nice alternative). All of these solutions attempt to capture the cyclical process of which data mining is a part.
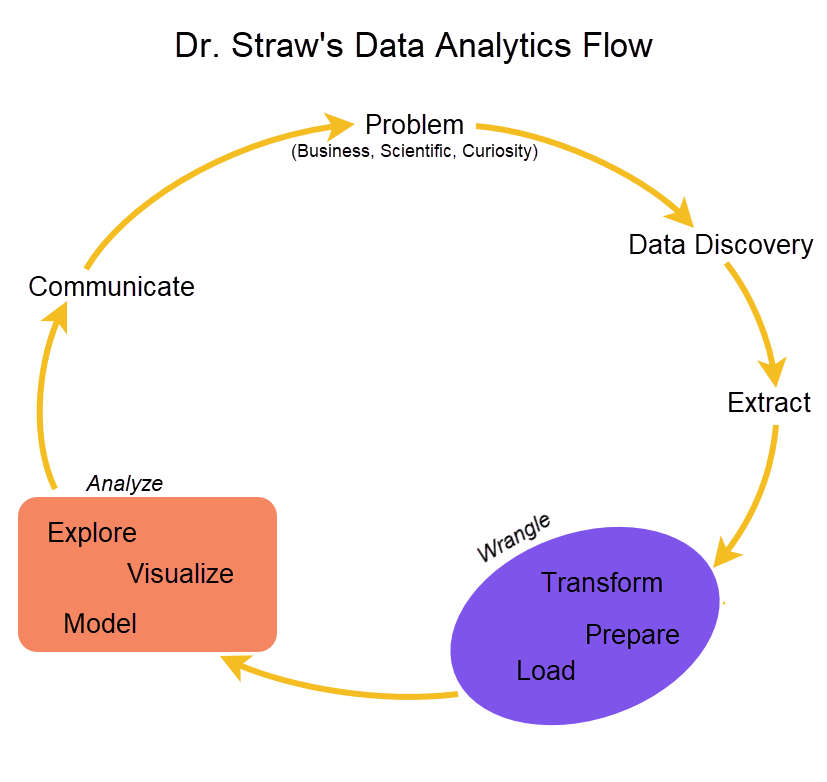
A.1 Model building examples using F1 data
Nigro (2020) has great project detail in Python, which could be ported to R with some work. The model building technique comparison under Findings is quite interesting. This project includes a GitHub page. GitHub is is a community based software repository.
Parris (2022) has interesting insights, but lacks project details that would enable anyone to duplicate this project.
Patil et al. (2023) used correlation analysis and principal component analysis (PCA) using R to analyze F1 race results.GitHub page
Sial (2022) has a linear regression model comparing number of wins and number of races. This model is at the bottom of the article. This article has some interesting visualizations. Unfortunately, the author chose to use animation on some visualizations, which distracts from the quality of the presentation. This project is based on a TidyTuesday project from 2021. This TidyTuesday project has a GitHub page with a lot of useful information and links.